Cartographer建图问题
本文共 500 字,大约阅读时间需要 1 分钟。
目前手上只有个16线的激光雷达,想在房间跑一下建图,目的是能够跑通就可以.
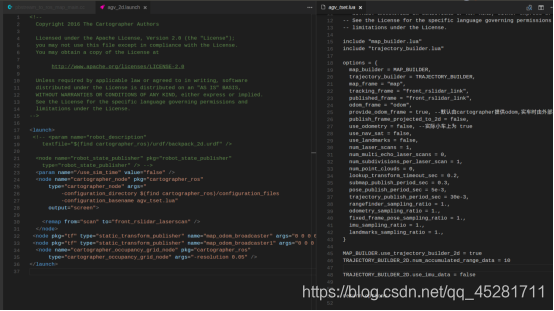
1,启动激光雷达, 2,将激光雷达3d点云转成2d laserscan数据类型 3,启动cartographer包roslaunch cartographer_ros agv_2d.launchCartographer配置:
终端报错:
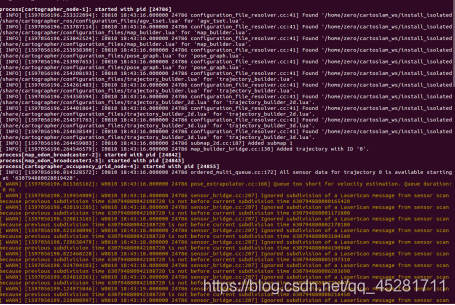
百度谷歌了一大圈:
都说是 的问题,我把它设置成false或者注释掉都不好使.大佬可有遇到过这种情况吗?解决:
激光雷达里面设置的仿真时间,去掉之后就好<arg name="time_synchronization" default="false" /> 来cartographer launch里面这个要打开,这是显示map的节点!!!
<node name="cartographer_occupancy_grid_node" pkg="cartographer_ros" type="cartographer_occupancy_grid_node" args="-resolution 0.05" /> cartographer包中的任何文件改动后均需要重新编译运行!!!
转载地址:http://fmntz.baihongyu.com/
你可能感兴趣的文章